![]()
Contents
This is the last online lesson for this course. Today we want to present you Kubernetes, a container orchestrator tool. But what is a container orchestrator? We will see it in a moment.
Monolithic vs Microservices
We recap briefly the difference between a Monolitich and Microservices architecture.
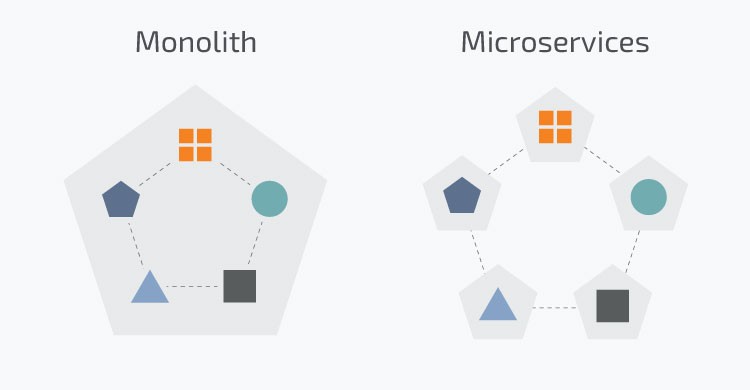
Monolitich
In a Monolithic application, all the functionalities are on a single deployable artifact. In big applications, a monolithic approach brings to a single huge codebase, and since everything has to roll out all together, deployments can take a long time. In addition to this, it could be the case that different parts of the application are managed by different teams and this can lead to additional complexity during deployment and to scaling issues (if you have a bottleneck on a single area you need to throw resources at the whole application, and this could take to over-provisioning issues).
Microservices
In a Microservices Architecture, instead of having a very huge application, each piece of functionality is split apart into smaller individual artifacts. If an update is necessary, you can update only the affected service. You can also scale up a single service on demand, instead of the overall application.
Having one machine for each service would require a lot of resources and hosts. One could choose a containerized approach (for example, using docker), where you have a process inside a machine that permits you to create and manage containers.
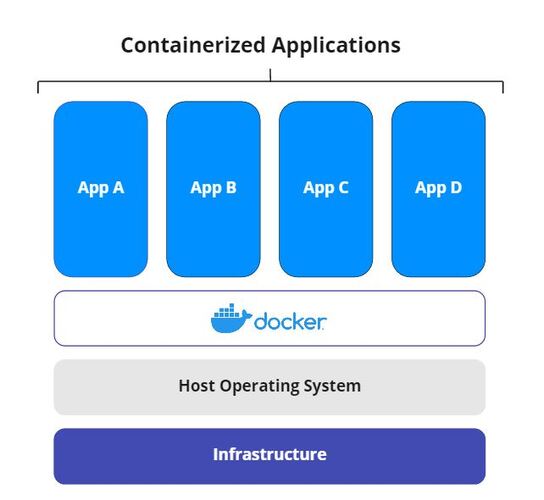 We saw some docker examples in the previous lessons, but how we can instruct containers to communicate with each other?
We saw some docker examples in the previous lessons, but how we can instruct containers to communicate with each other?
Container orchestration
We met docker-compose, a tool that permits the creation of a microservices-based application in a host. But in reality of the fact we have an application with services distributed over more than one host. To manage all these services, and to permit a smooth integration between them, we can use a container orchestration tool like Kubernetes.
What is Kubernetes
Kubernetes (aka K8s) is a container orchestrator: it is an open-source platform used for managing containerized workloads and services. It permits to run distributed systems resiliently, enabling scaling and failover capabilities. As a container orchestrator, it helps containers to work together and simplify the deployment of an application. Kubernetes works on a set of clusters of computers that are connected to work as a single unit. In every cluster live some containers of the application. Kubernetes automates the distribution and scheduling of an application container across a cluster. In other words: docker manages a set of containers (so it is a container runtime), while kubernetes manages and coordinates a set of container management software (or container runtime).
Cluster
A Kubernetes cluster is composed of:
- Control Pane: an entity that manages the cluster, coordinating activities such as scaling, updating, and scheduling.
- Nodes: a node is a virtual machine (VM) or a physical computer that serves as a worker machine in a cluster. Each node has a process called kubelet that manages the node and communicates with the control pane. Inside nodes run container runtimes (like, for example, Docker) that handle container operations. In Kubernetes is important the concept of Pod: a Pod is a group of one or more containers, with shared storage, namespaces, and resources, and a specification for how to run containers. Containers in a Pod are automatically co-located and co-scheduled on the same physical or virtual machine in the cluster (they run in the same shared context). The idea is to use a Pod to model an application-specific logical host (a Pod should contain one or more containers that are relatively coupled).


Control Pane Components
Control Pane makes global decisions about the cluster and detects and responds to cluster events. Components of the Control Pane can run on any machine in the cluster. Control Pane Components are:
- kube-apiserver: this component is the front end for the Kubernetes control pane.
- etcd: it is a distributed key-value store used to hold and manage critical information about the overall cluster.
- kube-scheduler: this component has the duty to assign a node to newly created Pods, taking into account some factors like data locality, interworkload interferences, constraints on hardware or software, etc.
- kube-controller-manager: it runs controller processes. A controller process is a process responsible for watching the state of the cluster’s node component and regulating the state of the overall cluster. An important controller is the Node controller, that is responsible for noticing and responding when nodes go down.
- cloud-controller-manager: the Cloud Controller Manager embeds cloud-specific control logic, letting the developer link cluster into a cloud provider’s API. Even if this is not a required component, a Could Controller Manager allows to leverage of many of the cloud provider features (such as load balancing, node controller (for example enabling the capability to manage nodes from the cloud provider user interface), route controller (to manage firewall rules)).
Node Components
Node components run on every node in the cluster.
- kubelet: this component makes sure that containers are running in a Pod.
- kube-proxy: it maintains network rules on nodes, that permit communication between Pods inside or outside of the cluster.
- container-runtime: it is responsible for managing the execution and lifecycle of containers within the Kubernetes environment.
More details about Cluster components can be found here.