![]()
Contents
In our Students’ Application, we implicitly made use of the HTTP protocol. In this section, we want to define what HTTP is, and how it works.
What is HTTP
HTTP (HyperText Transfer Protocol) is the principal communication protocol for the web. We are using HTTP everywhere: when we search for something on Google when we watch a video on YouTube, and even when we send an email through a web client.
HTTP is a client/server protocol: this means that there is an entity (the client) that sends a request to another one (the server) and the latter responds something to the first. Every time you visit a webpage from a browser, you submit a form or you click a button that triggers something on the server, you are doing a HTTP request.
HTTP in action
To see an example of how the HTTP Protocol works, let’s open our browser and go to www.google.com. Now, open the Network tab of the Develop Tools (right-click on the page, Inspect element, Network tab). The Developer Tools is a set of web tools that help developers understand what’s going on inside a page. From here, you can for example see the content of the web page in HTML, edit the styling, debug the client side of the web application (i.e. the code that your browser executes that permits you to interact with the application), and monitor network activities.
In the Network tab, we have all the HTTP requests that our browser (that acts as a client) performs over one or more servers.
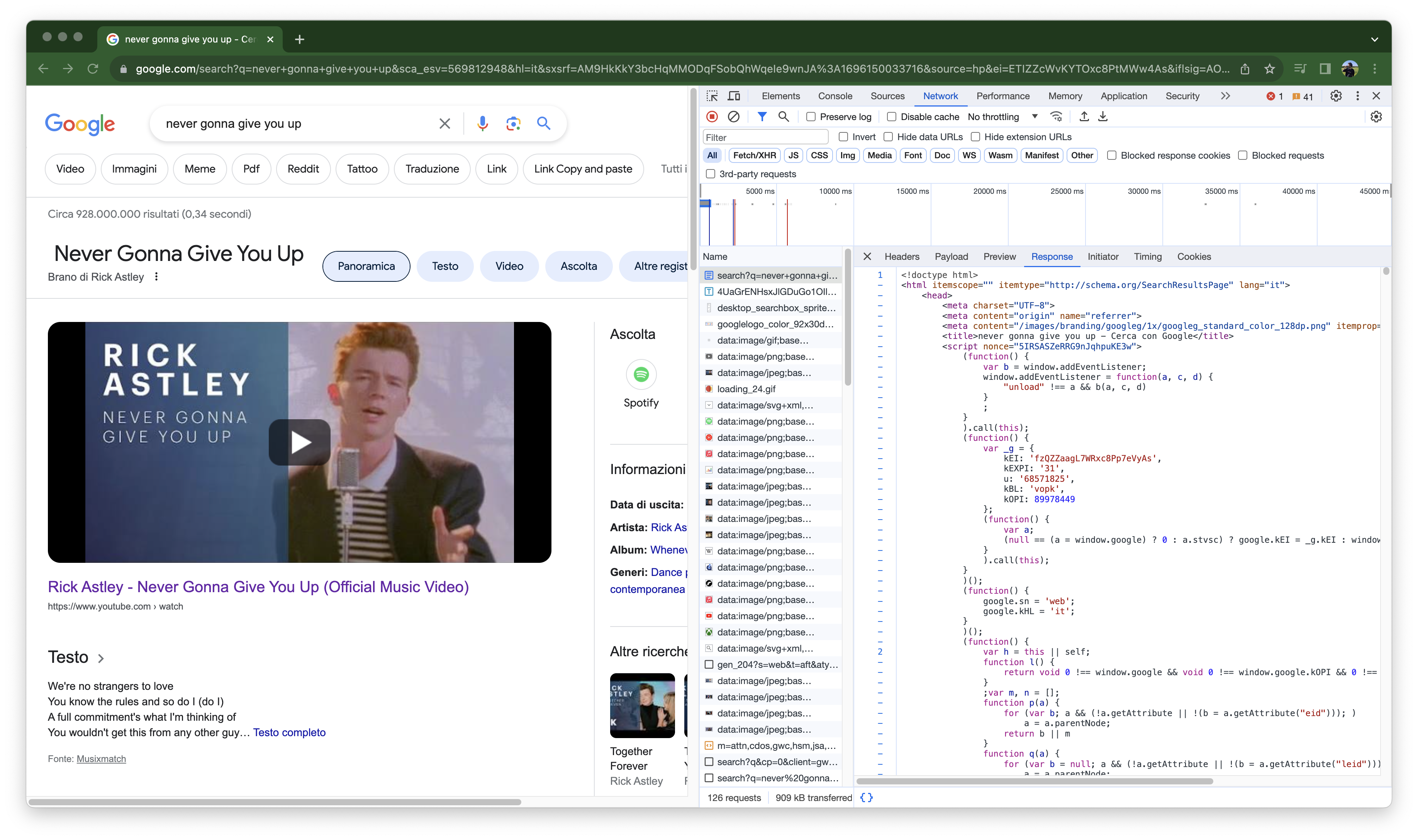
Search something on Google, and see the content of the Network tab. You should have a request with name search?q=something. Click on it.
With this action, we are going to inspect the internal details of the HTTP Call. We can see the response that a server gives to us in the tab Response (in our case, an HTML page):
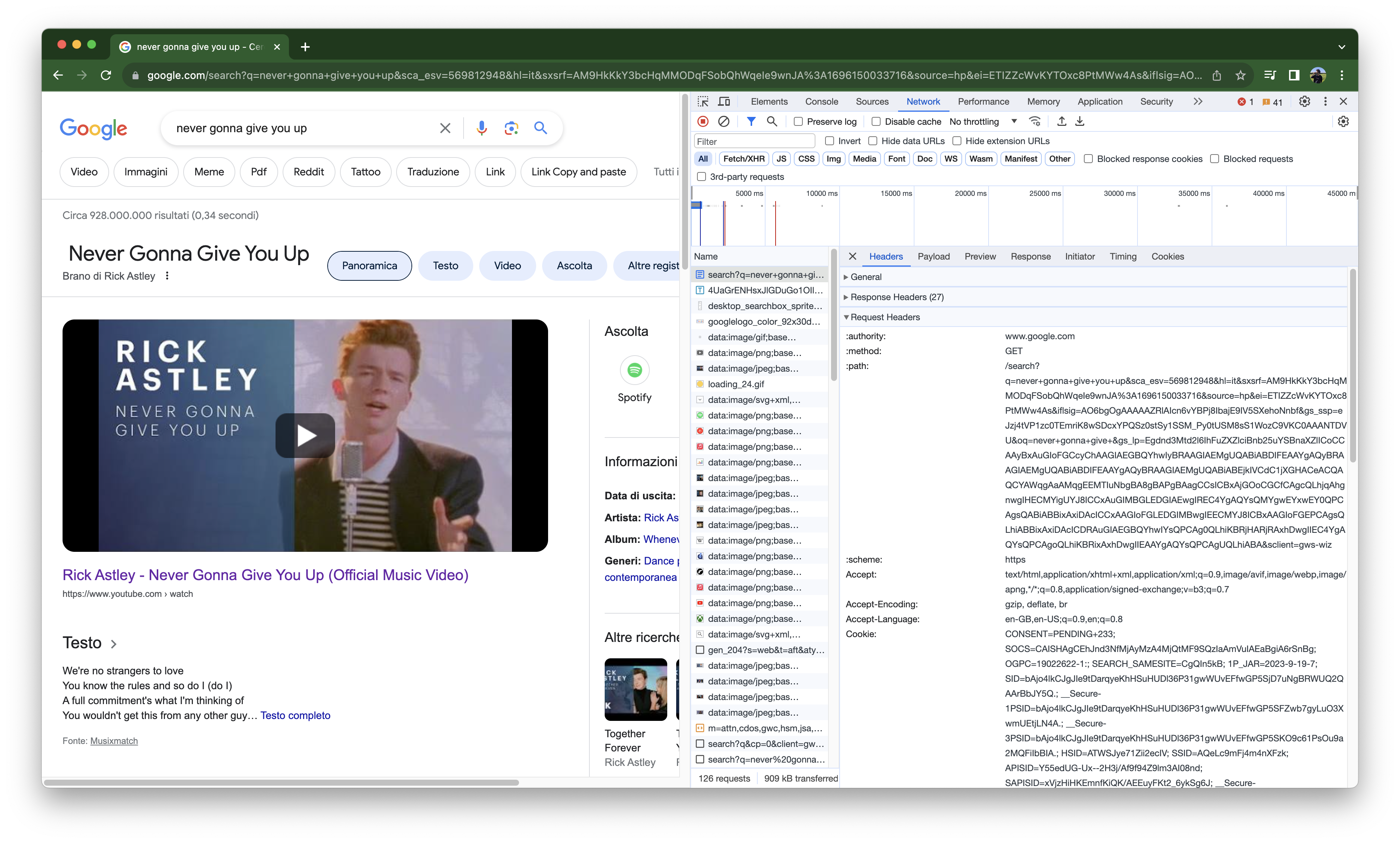
 And other information such as Headers and Payload (more information on these concepts later):
And other information such as Headers and Payload (more information on these concepts later):
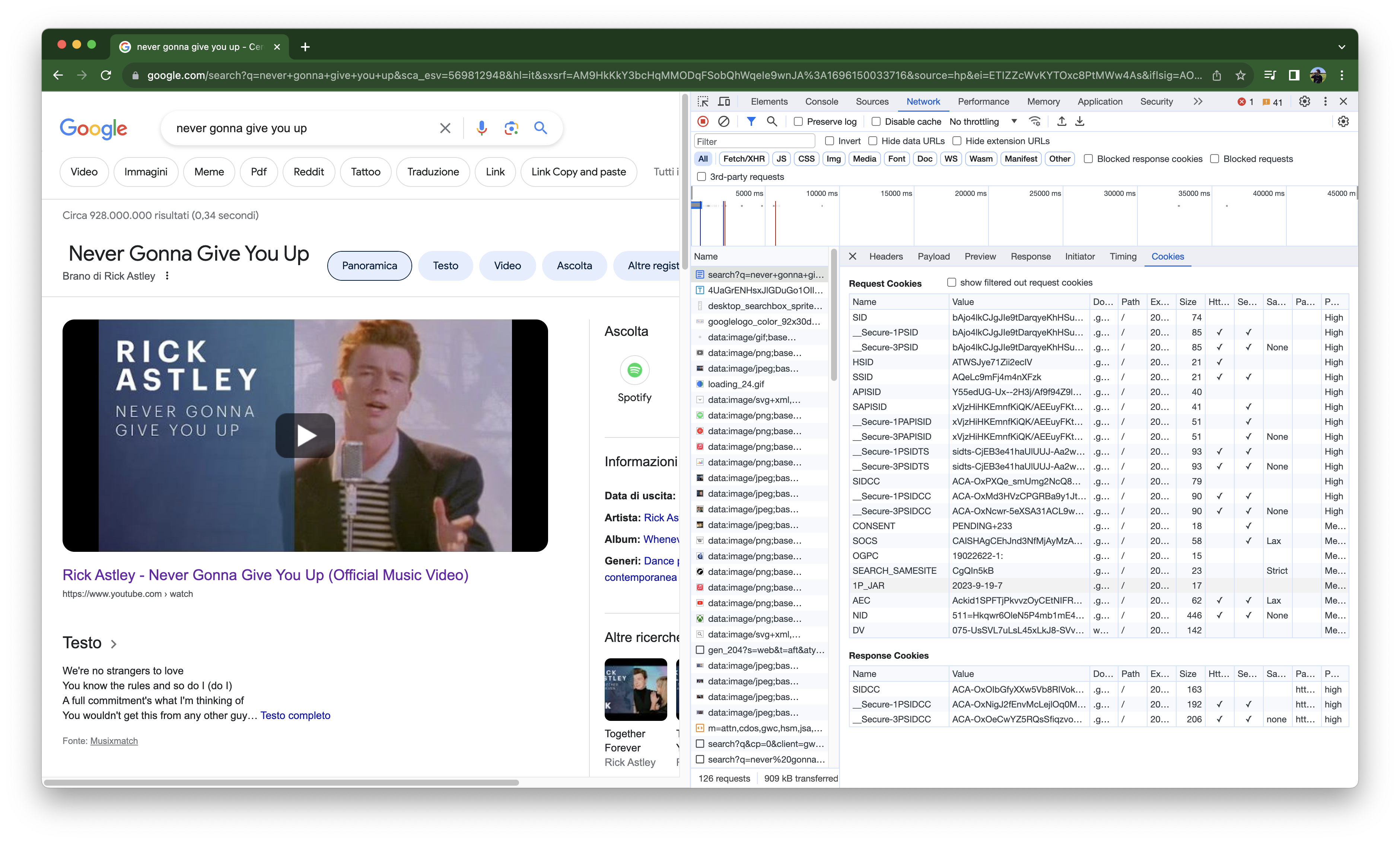
Structure of an HTTP call
From the previous example, we can deduce that an HTTP Request is composed of Headers and a Payload, and an HTTP Response of Headers and the response itself.
The Payload is composed of Params (that is, the HTTP query string) and a Body. A Payload permits enhancing the request by adding information. In our example, we don’t have a Body, and the information is passed only through a query string (have a look at the URL). The explanation of body and query string will arrive shortly, for now just focus on the structure.
The Header part contains key-value pairs.
Headers
Inside Headers, we have information about the request and response. Typically a Request Headers section contains information about the User Agent (i.e., the name of the application that is going to make the request), the Content Type (the format of the Request body, if we have one), and permits to pass credentials for authentication to the server.
In Response Headers, we might have the content type and the encoding of the body received from the server, caching directives, and others.
An exhaustive list of standard headers is available here.
General Headers
From the Network tab probably you have noticed an additional header section, General Headers. Headers inside this section are not the same as Request and Response. Request/Response Headers contain information about the content of the message, while General Headers contain information about the message itself, for example: the status code, the request method, and the server address.
Status Code
Status Code tells us the status of the HTTP Call. It is a three-digit integer and all valid status codes are within the range 100-599. The first digit has a categorization role:
- 1xx: Information responses: we use 1xx to inform the client about the status of the request. For example, we can use the 102 (Processing) status code to inform the client that the server has accepted the request but has not yet completed it (i.e., it requires a lot of time to process the request). 1xx status code is not properly supported by a web browser and it is used very rarely.
- 2xx: Successful responses: in this group, we have the status codes to use when the request is satisfied correctly. Some examples of status codes that fall under this categorization are:
- 200 OK: tells that the request has succeeded. In the body, we have the response to the call.
- 204 NO CONTENT: tells that the request has succeeded and there is no additional content (i.e., no body).
- 3xx: Redirection messages: this means that further action needs to be taken by the user agent (i.e. the client) in order to fulfill the request (for example, performing a redirect).
- 307 TEMPORARY REDIRECT: indicated that the target resource has temporarily been assigned to a new location.
- 308 PERMANENT REDIRECT: indicated that the accessed resource has been assigned permanently to a new location.
- 4xx: Client error responses: there is a problem with the request.
- 400 BAD REQUEST: the server cannot process the request because it is malformed.
- 401 UNAUTHORIZED: the server cannot process the request because there is a lack of valid authentication credentials for the resource.
- 403 FORBIDDEN: the server cannot process the request because the user does not have enough permissions to access the resource. Note that this is different from 401: with 401 we say that there is a lack of authorization, with 403 we say that the user has insufficient access.
- 404 NOT FOUND: the server did not find the requested resource.
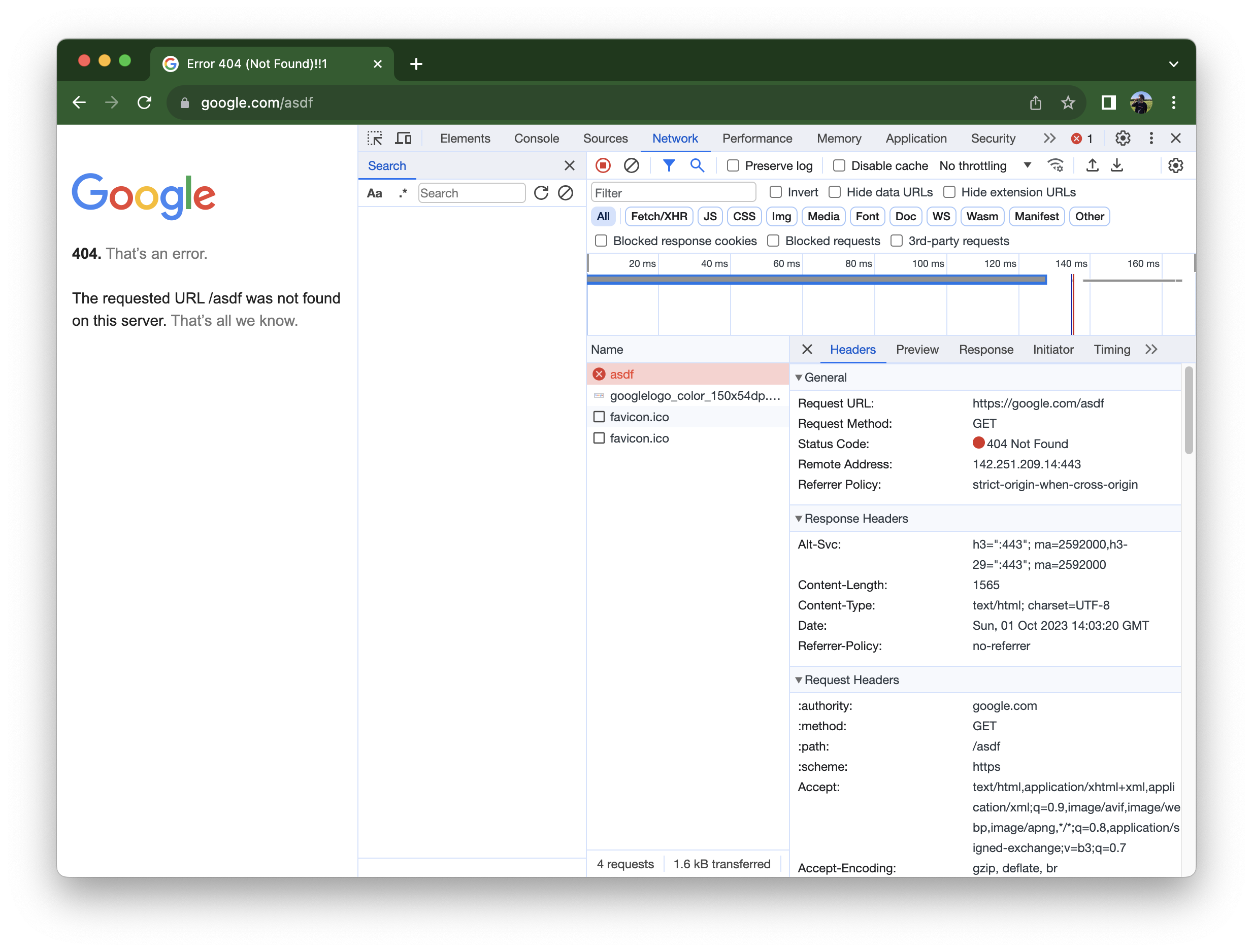
- 418 I’M A TEAPOT: well, this is not a standard status code but comes from a 1998’s April’s Fools (if you want a laugh here is the proposed standard). However, since Computer Scientists are very funny people, some HTTP libraries (like the one shipped with the Spring Framework) implemented this status code!
- 5xx: Server error responses: a 5xx status code means that the problem is server-side.
- 500 INTERNAL SERVER ERROR: the server encountered an unexpected condition that prevented it from fulfilling the request.
- 501 NOT IMPLEMENTED: the server does not support the functionality required to fulfill the request.
- 502 BAD GATEWAY: it means that the server received an invalid response from another server.
Details about status codes (and the protocol in general) can be found in the official proposed standard. Status Code helps the client application to better understand the response.
Request Methods
An HTTP request has an associated method, that semantically indicates the purpose of the request. There are 9 different methods: GET, POST, PUT, PATCH, DELETE, CONNECT, TRACE, OPTIONS. We will talk briefly about the meaning of the first five.
- GET: an HTTP GET request permits the retrieval of information from a server. When you open the main page of Google, for example, your browser will do a GET request and the server will respond with the HTML of the frontpage.
- POST: POST permits to push something on the server. You use this method when you need to create a new resource in the server or to provide to the server a block of data (for example, fields of an HTML form). Usually after a successful POST, you return a 201 status code or for special cases (depending on the implementation) a 200 with information that can be used by the client for subsequent GET requests to the newly created resource.
- PUT: a PUT request says that the resource must be created (if not exist in the server) or replaced (if exists).
- PATCH: PATCH permits to edit some information of a resource. The main difference from a PUT is that the resource must already exist in the server and that permits partial update of the resource.
- DELETE: DELETE permits to deletion of a resource from the server.
Body
The Body part of an HTTP packet is sent just right after the header part. Here, we insert the content (a.k.a message) of the request. In this field, we have also the response from the server. The type of the content inside the body should be defined in a special HTTP Header, Content-Type. The length of the message can be passed to the user agent in the Content-Length header.